AWS Data in Real Life
7 Oct 2025
Modern organizations generate data at massive scale — IoT sensors, ERP systems, CRM tools, and cloud applications.
To transform this chaos into insights, data engineers rely on cloud-native pipelines.
🏗️ Architecture Overview
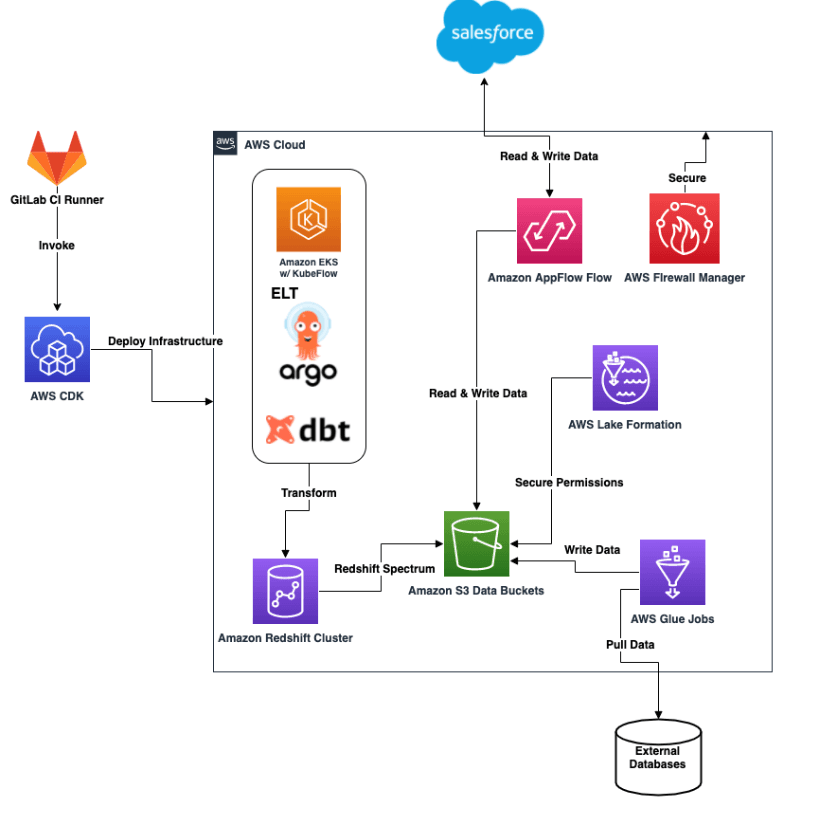
The architecture starts from S3, where raw data lands.
Glue jobs perform ETL to clean and prepare it, storing it back into structured “Silver” and “Gold” layers.
These layers feed analytics through Athena and QuickSight, while heavy transformations or training workloads use EMR or SageMaker.
⚙️ Data Flow Steps
- Ingestion – Stream or batch data into S3 using Kinesis or Firehose.
- Transformation – Process with Glue jobs written in PySpark.
- Querying – Query curated data via Athena with SQL.
- Analytics – Build dashboards in QuickSight for stakeholders.
🔍 Example Glue Job
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
glueContext = GlueContext(SparkContext.getOrCreate())
df = glueContext.create_dynamic_frame.from_catalog(database="bronze", table_name="sales_raw")
df_clean = DropFields.apply(frame=df, paths=["_corrupt_record"])
glueContext.write_dynamic_frame.from_options(
frame=df_clean, connection_type="s3", connection_options={"path": "s3://my-lakehouse/silver/sales"}, format="parquet"
)